설명하기 위해 쓴 글은 아니며 혼자 공부하며 정리한 내용입니다.
좋은 자료 :
https://welcome-to-dewy-world.tistory.com/108
1. Attention Is All You Need
좋은 기회로 ML Research 인턴을 할 수 있게 되었는데, 이래 저래 논문을 많이 볼거 같아서 아예 게시판을 하나 새로 팠다... 열심히 써야지... 논문... 화이팅...!!!!!! 내 인생도 화이팅!!!!!!!!! Attention I
welcome-to-dewy-world.tistory.com
https://jalammar.github.io/illustrated-transformer/
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2, Vietnames
jalammar.github.io
임베딩벡터간의 유사도를 알 수 있는 이유
- 'The squad is ready to win the football match'
- 'The team is prepared to achieve victory in the soccer game'
- 위 두 문장은 의미는 같지만 비슷한 단어가 거의 없다.
- 하지만 각 문장의 임베딩 벡터에서는 의미적 인코딩이 매우 유사하기 때문에 임베딩 공간에 서로 가까이 놓인다. => 이게 워드 임베딩을 하면 문장의 유사도를 알 수 있는 이유 아닐까?

[딥러닝] 인공신경망의 Embedding이란?
사람이 사용하는 언어나 이미지는 0과 1로만 이루어진 컴퓨터 입장에서 그 의미를 파악하기가 어렵다. 예를 들어 인간의 자연어는 수치화되어 있지 않은 데이터이기 때문에 특징을 추출해 수치
velog.io
벡터의 내적과 딥러닝
1. 벡터의 내적은 방향이 완전 반대면 0이고 벡터가 같으면 내적의 값이 최대가 됨. 즉 벡터의 내적이란 두 벡터의 유사도를 의미함 => 자연어에서는 두 단어사이의 내적한 결과(유사도)를 기반으로 유사도가 높은 것을 계속해서 학습해 나감.
2. 행렬의 모든 원소를 곱하는 것을 벡터의 내적으로 한번에 연산할 수 있음 => 연산이 빨라지는 트랜스포머의 장점임
Scaled Dot Product Attention에 관한 좋은 글
1. https://simpling.tistory.com/3
Transformer(1) - Scaled Dot-Product Attention
Transformer를 이해하기 위해서는 우선 Self attention에 대한 이해가 필요하다. 셀프 어텐션은 문장에서 각 단어끼리 얼마나 관계가 있는지를 계산해서 반영하는 방법이다. 즉, 셀프 어텐션으로 문장
simpling.tistory.com
2. https://gaussian37.github.io/dl-concept-transformer/
- Linear 연산을 통해 Q, K, V의 차원을 감소하는 것은 모델이 어느 특정한 차원들만 선택해서 보겠다는 것을 의미합니다. h개의 방법으로 차원을 축소해서 보되 병렬적으로 전체를 검토하게 되므로 병렬 연산으로 연산 속도는 증가 시키면서 다방면으로 모델이 학습할 수 있도록 합니다.
- concat을 하게 되면 채널이 커질 수 있기 때문에 출력 직전 Linear 연산을 이용해 Attention Value의 차원을 필요에 따라 변경할 수 있습니다.
Attention 메커니즘
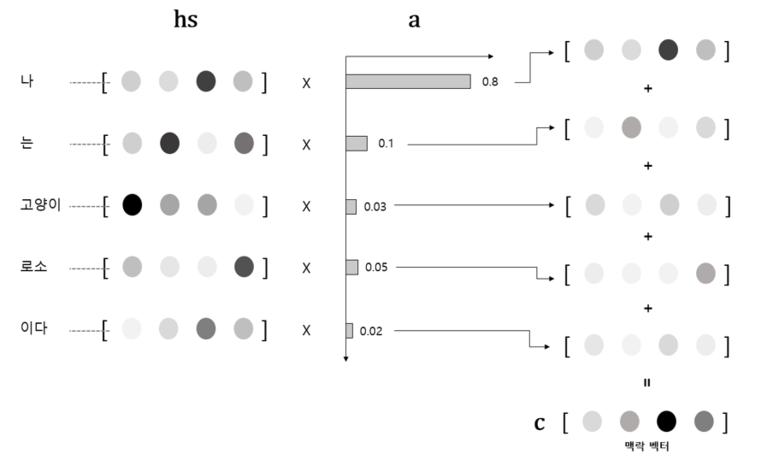
- 어텐션 스코어 (Attention Score) :현 시점의 디코더의 Hidden State (st)와 인코더의 모든 Hidden State들과 각각 내적을 수행한다. 어느 인코더의 Hidden State를 얼마나 참고할지를 결정해야 한다. 이 때, 현재 예측에 필요한 정도라고 판단되는 점수를 어텐션 스코어 (Attention Score)라고 한다.
- => 현시점의 디코더의 hidden state(st)값과 인코더의 모든 hidden stae(hn)을 내적하면 두 벡터간의(하나의 벡터는 인코더에서의 하나의 벡터의 0부터 n까지 이고 다른 하나는 어떤 디코딩할 단어의 벡터)유사도를 구할 수 있다. 즉 디코딩할 단어와 인코딩한 모든 단어간의 유사도를 구해서 점수를 매긴다. => 내적하면 항상 스칼라값이 나오므로 이 스코어를 softmax를 취해주면 attention 분포를 구할 수 있을 것이다.
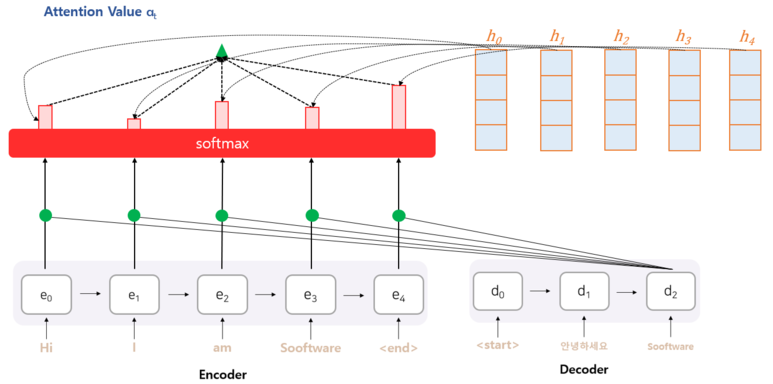
Attention Distribution X Encoder Hidden State
소프트맥스를 통해 얻은 어텐션 분포를 각 인코더 Hidden State와 곱해준다.
(Broadcasing)
Weight Sum
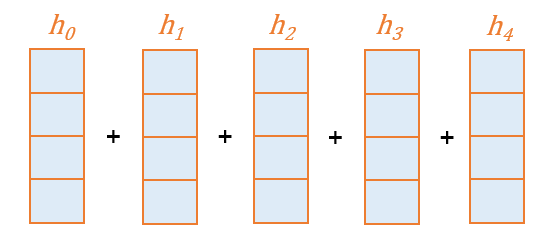
Weight Sum
각 어텐션 분포와의 곱을 통해 얻어진 Hidden State들을 전부 더해준다.
(element-wise)
이렇게 얻은 벡터를 인코더의 문맥을 포함하고 있다하여 컨텍스트 벡터(Context Vector)
word embedding vector가 512인 이유
이건 하이퍼파라미터이다. 즉 우리가 설정할 수 있는데 일반적으로 그 글에서 가장 긴 문장의 길이와 일치한다.
갑자기 query, key, value가 나오는 이유
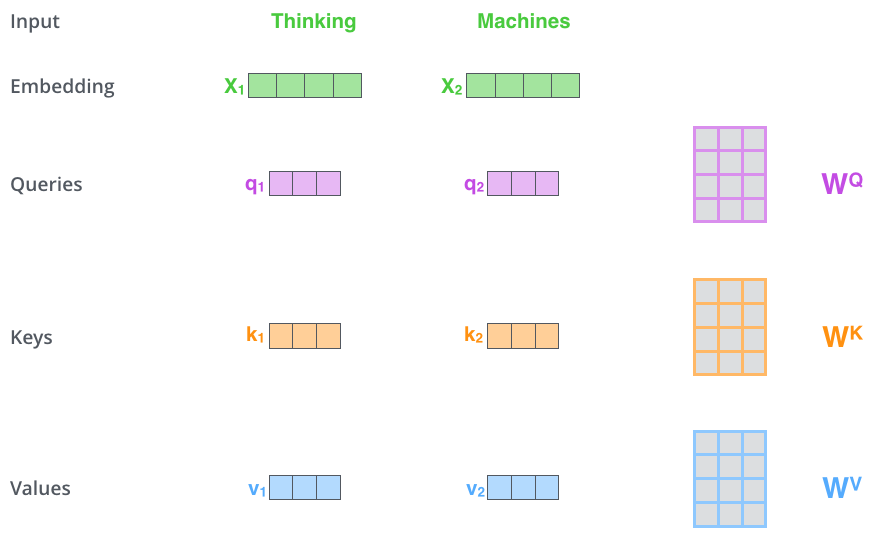
선형대수학의 linear transformation이라고 한다. 즉 word embedding을 선형결합하여 query, key, value형태로 나누는 것. 굳이 하는 이유는? 차원을 줄이기 위해서라고 이해하였다.
(Their dimensionality is 64, while the embedding and encoder input/output vectors have dimensionality of 512)
'인공지능 > 딥러닝' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] ResNet 용어 정리 및 코드 분석 (0) | 2023.05.30 |
|---|---|
| GAN: Generative Adversarial Nets 논문 리뷰 (0) | 2023.05.06 |
| Imagenet classification with deep convolutional neural networks 정리 (0) | 2023.03.02 |
| 신경망 학습의 전반적인 과정 (0) | 2022.12.27 |
| 코딩애플 딥러닝 강의 후기 (0) | 2022.12.19 |